
我最近为什么要研究这个“搜人引擎”的玩法?说起来挺郁闷的。去年年底,我在网上随便填了个表,结果被一个卖理财课的销售天天轰炸。最气人的是,他不仅知道我的手机号,连我以前住在哪儿,在哪儿上过班都知道得一清二楚。
我开始实践:从零开始“偷”数据
当时我就火了,我就想,这些混蛋到底是怎么把我的信息拼凑起来的?他们是不是有什么特殊的渠道?我决定自己动手试试,看能不能复刻出他们的工作流程。
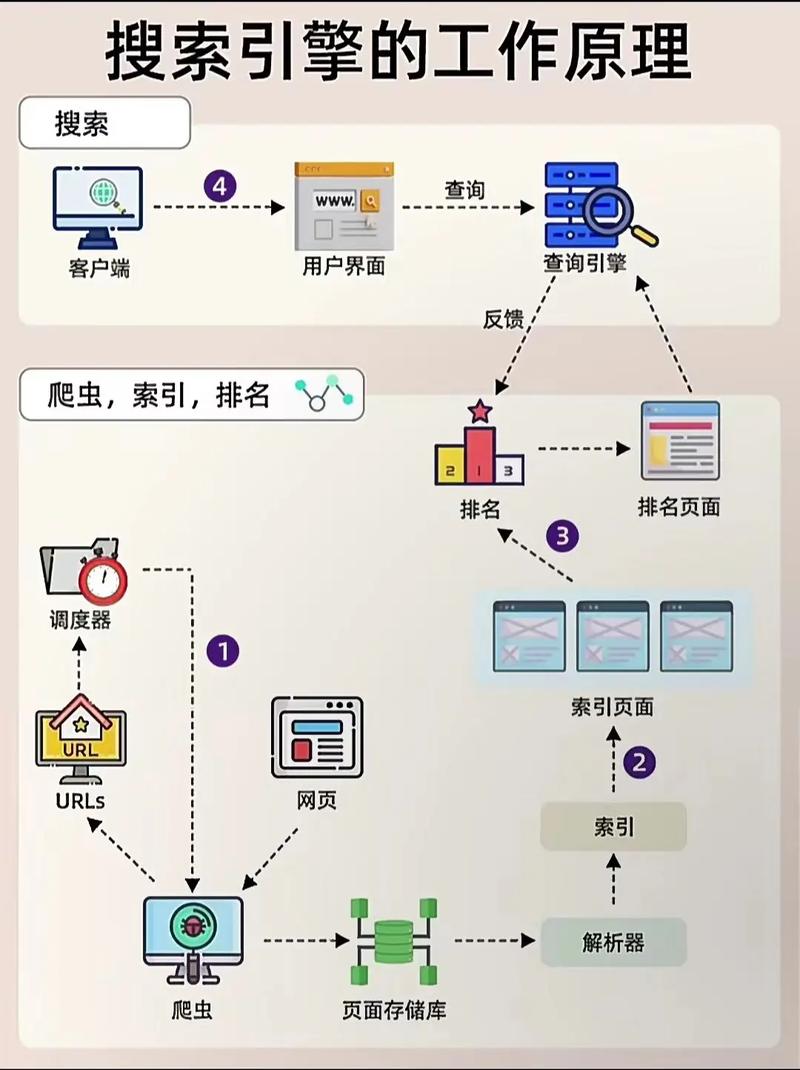
第一步:广撒网,爬!
我给自己写了一个很粗糙的小机器人,这玩意儿干的活儿就是满世界去爬数据。专业的说法叫爬虫,但本质就是个数字小偷。它不会像谷歌那样只抓网站的主页,它专挑那些犄角旮旯、没人打理的旧论坛、招聘网站的废弃简历页,甚至是一些根本没有做安全防护的公开数据库接口。
- 我重点找那些十年前的博客和论坛。这些地方的数据很老,但用户的昵称和QQ号往往是真的。
- 然后是那些小公司的招聘系统。很多小公司招完人,根本不删简历,上面手机号、身份证信息、家庭住址,全都堆在那里。
第二步:数据清洗与标记
光爬回来一大堆乱码没用,得把这些数据都变成能用的“标签”。比如,我从A网站拿到了一个昵称叫“老王爱吃面”的人,他在B网站留了手机号,在C网站说自己住在某个小区。
第三步:恐怖的“对齐”过程
这才是搜人引擎最可怕的地方。它不需要你提供完整的身份信息。只需要一个微小的共同点,它就能把这些碎片化的数据强行“对齐”。
比如,如果“老王爱吃面”在A网站的注册邮箱是123@*,而在B网站的简历上,那个手机号的主人也用了123@*这个邮箱作为联系方式——好了,手机号和昵称就绑定了。然后它会继续找,直到把这个人在全网的所有碎片都像拼图一样拼起来。
一旦对齐完成,这个人的身份画像就出来了:他的真实姓名、工作单位、家庭地址、以前的爱甚至他在哪个交友网站上注册过,全都能清清楚楚地拉出来。
我为什么能这么快搞懂?
我之所以对这种“搜人”流程这么熟悉,不是因为我以前就是干这个的,而是因为几年前我经历了一件糟心事。
当时我一个亲戚被人骗了一大笔钱,对方跑得无影无踪。报警了,警察说线索太少,不好找。亲戚急得跳脚,我就说我试试看能不能用技术手段把那家伙挖出来。
我用上面说的这个流程,花了不到一个星期的时间。我先从那个骗子以前用过的一个社交账号入手,通过交叉比对,找到了他十年前在一个游戏论坛上的留言,里面有他老家的地址和真名。
再通过真名和地址,我在一个已经被黑客攻击过的旧数据库里,找到了他早年的手机号。通过手机号反查,找到了他最近的活动轨迹和藏身地。
当把一整张密密麻麻的个人信息表递给亲戚的时候,我心里发凉。我不是专业的侦探,我只是利用了那些被人遗忘的数据漏洞。这事儿让我彻底明白,在互联网上,你发的每一个字,留下的每一个足迹,只要被人用心去收集和对齐,你就等于在光天化日之下裸奔,根本没有隐私可言。





